Introduction
NEXUS is an end-to-end, cloud-native AI data intelligence framework designed to transform fragmented enterprise data into actionable, secure, and context-aware insights.
It seamlessly ingests data from diverse systems of record, standardizes and enriches it through scalable processing pipelines, and transforms it into high-dimensional embeddings stored across vector databases and knowledge graphs.
By enabling deep semantic understanding and relationship-driven intelligence, and integrating advanced retrieval techniques with governed AI orchestration, NEXUS empowers enterprises to unlock real-time insights, drive intelligent automation, and scale AI adoption seamlessly across multi-cloud environments.
Overview
A unified framework that transforms distributed data into a governed, context-aware knowledge layer — enabling teams to build AI-powered applications, semantic discovery, and secure multi-model interactions across cloud platforms.
With built-in AI guardrails and governance — including policy enforcement, hallucination mitigation, PII protection, and prompt security — the platform ensures all AI-driven interactions are accurate, compliant, and aligned with enterprise standards.
Designed for multi-tenant environments and cloud-agnostic deployments, the framework enables seamless integration with existing enterprise ecosystems while providing a scalable and extensible foundation for next-generation, data-driven AI solutions.
Unified Knowledge Layer
Turn distributed enterprise data into a governed, context-aware layer ready for AI applications.
Built-in Guardrails
Policy enforcement, hallucination mitigation, PII protection, and prompt security — included by default.
Multi-Cloud, Multi-Tenant
Cloud-agnostic deployments with strict tenant isolation — built for enterprise scale and compliance.
High-Level Architecture Overview
The framework is delivered as a production-ready, modular, and extensible architecture, designed for rapid adoption and seamless integration into existing enterprise ecosystems. It comprises a set of well-defined, interoperable layers, all supported by a cross-cutting Security, Governance, and Observability layer.
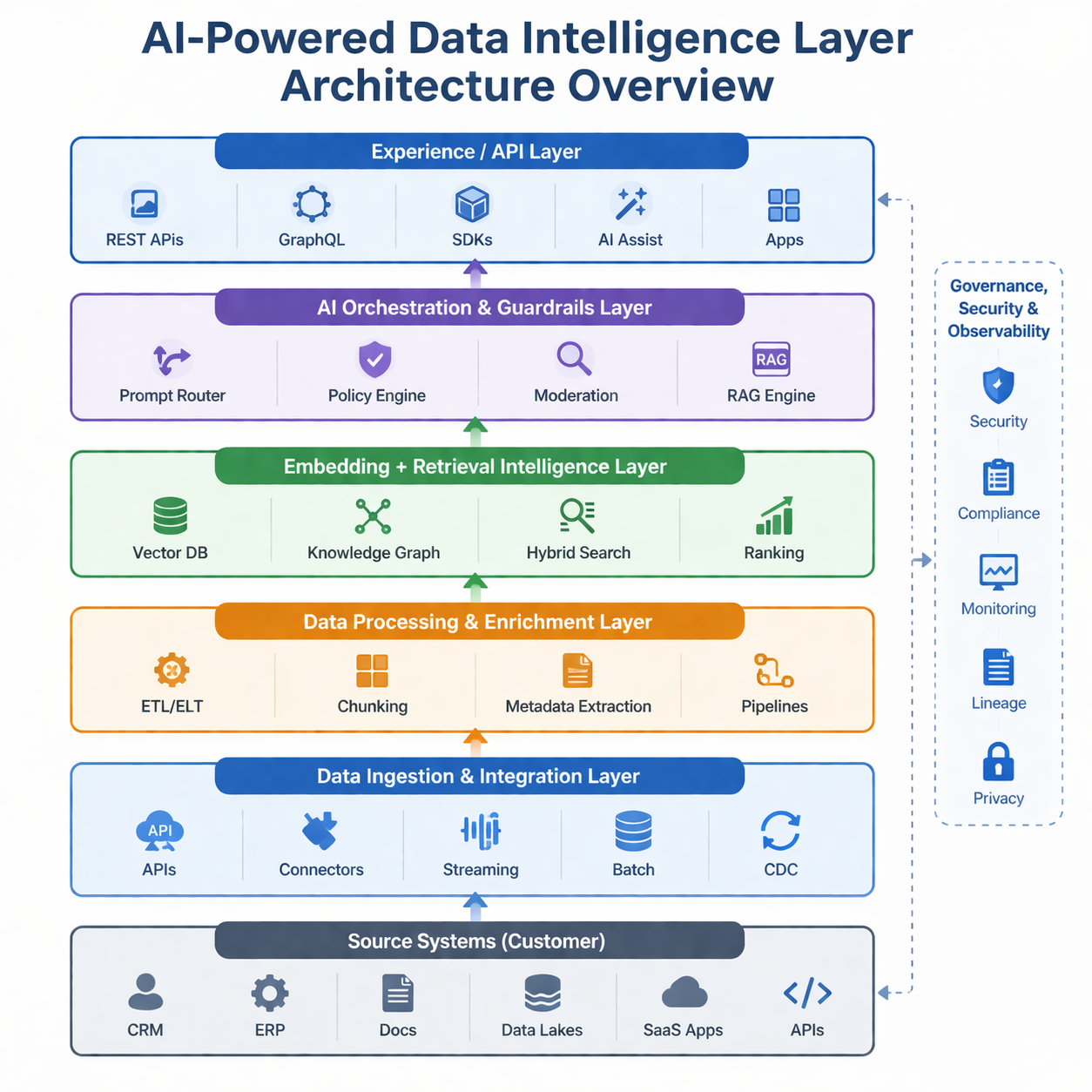
Each layer is pre-integrated and configurable, enabling organizations to quickly enable capabilities without extensive custom development. The architecture supports plug-and-play deployment, allowing enterprises to adopt the framework as-is or extend and customize specific components to align with their unique business, technical, and compliance requirements.
Component-Level Design
The framework is composed of six layered components — five sequential layers in the data and AI pipeline, plus a cross-cutting governance layer that integrates with every stage.
Enterprise Data Sources
The primary source of enterprise data, encompassing information captured from the organization's diverse operational and business systems, including:
- CRM systems — customer and relationship data
- ERP systems — finance, supply chain, and operations
- Documents — PDFs, presentations, emails, reports
- Data lakes & data warehouses
- SaaS applications — e.g. Salesforce, Workday
- External and third-party APIs
Data Ingestion & Integration
A robust data pipeline designed to securely ingest and integrate data from diverse enterprise source systems into the platform — ensuring reliable, scalable, and near real-time data movement while preserving data integrity and consistency.
Key capabilities
- APIs & Connectors — Standardized and custom integrations to connect with enterprise systems and external services.
- Streaming Ingestion — Real-time data pipelines for event-driven and low-latency processing.
- Batch Processing — Efficient handling of large-scale data transfers at scheduled intervals.
- Change Data Capture (CDC) — Incremental data synchronization by capturing and propagating updates from source systems.
Data Processing & Enrichment
Transforms raw, ingested data into structured, standardized, and AI-ready formats — enhancing data quality and enriching it with contextual information to support downstream analytics, retrieval, and AI/ML processing.
Key capabilities
- ETL/ELT Processing — Data cleansing, normalization, transformation, and standardization.
- Document Chunking — Segmenting large documents into smaller, context-preserving units optimized for AI and retrieval workflows.
- Metadata Extraction — Deriving and attaching contextual attributes such as tags, entities, classifications, and relationships.
- Automated Data Pipelines — Orchestrated workflows for continuous processing, enrichment, and data lifecycle management.
Embedding & Retrieval Intelligence
Transforms processed data into rich semantic representations and enables intelligent retrieval of contextually relevant information — integrating vector-based embeddings with graph-based relationships to form a unified knowledge layer that empowers AI systems to understand meaning, context, and interconnections across enterprise data.
Key components
- Vector Database — Stores high-dimensional embeddings to capture the semantic meaning of structured and unstructured data, enabling similarity search and contextual retrieval.
- Knowledge Graph — Models relationships and connections across entities, enhancing contextual understanding and enabling graph-based reasoning.
- Hybrid Search — Combines lexical (keyword-based) and semantic (embedding-based) search to deliver more accurate and comprehensive results.
- Ranking & Re-ranking — Applies relevance scoring and optimization techniques to ensure the most contextually appropriate results are returned.
AI Orchestration & Guardrails
The control and governance center for AI interactions with enterprise data — orchestrating intelligent workflows while enforcing safety, compliance, and contextual accuracy, ensuring all AI-driven outputs are grounded, policy-compliant, and aligned with enterprise standards.
- Prompt Injection & Leakage Prevention — Safeguards the system against malicious or adversarial prompts by detecting unsafe instructions and preventing data leakage.
- Policy Enforcement — A flexible and configurable framework to enforce organization-specific policies, regulatory requirements, and domain standards across all AI interactions.
- Off-topic Detection — Ensures user queries are relevant to the intended context by classifying inputs using embedding similarity thresholds and dedicated classification models.
- Hallucination Mitigation — Enforces grounded and accurate AI responses by validating outputs against trusted data sources via RAG with source citations, confidence scoring, and output verification.
- PII Detection & Masking — Identifies and protects sensitive information (SSNs, emails, personal identifiers) within inputs and outputs using detection tools such as Microsoft Presidio and AWS Comprehend.
- RAG (Retrieval-Augmented Generation) Engine — Facilitates grounded AI interactions by dynamically retrieving relevant, tenant-specific data from curated knowledge sources and incorporating it into model responses.
Experience / APIs
The engagement layer — enabling systems and users to onboard, access, and interact with AI services through applications, assistants, dashboards, and APIs. It delivers AI-driven capabilities through standardized interfaces, ensuring seamless integration and consistent consumption of intelligent services across multiple channels.
- REST APIs / GraphQL — Developer-friendly interfaces for integrating AI services into enterprise applications.
- SDKs — Pre-built libraries and tools to accelerate integration and customization.
- AI Assistants — Conversational interfaces including chatbots, voice agents, and copilots for intuitive user interaction.
- Web & Mobile Applications — User-facing applications delivering personalized, context-aware experiences.
Security, Governance & Observability
This cross-cutting layer enforces end-to-end security, governance, and observability across the platform — ensuring that all data and AI interactions are protected, policy-compliant, and auditable. It safeguards enterprise data through robust access controls, encryption, and continuous monitoring while maintaining regulatory compliance and operational transparency.
- Role-Based Access Control (RBAC) — Enforces fine-grained access permissions based on user roles and responsibilities.
- Tenant-Level Data Isolation — Guarantees strict logical and/or physical separation of data across tenants, preventing unauthorized access in multi-tenant environments.
- Encryption — Secures data both in transit (TLS) and at rest using industry-standard encryption protocols.
- Audit Logging — Comprehensive logging and traceability of system activities, user interactions, and AI operations.
- Observability & Monitoring — Real-time monitoring, logging, and distributed tracing across data pipelines, system services, and AI interactions.
Compliance & regulatory alignment
Designed to align with industry and regulatory standards, including:
Deployment
The framework is optimized for plug-and-play deployment, enabling enterprises to quickly integrate with existing ecosystems, onboard new tenants, and scale horizontally without architectural changes.
Its modular design supports selective deployment of components, making it adaptable for a wide range of enterprise use cases — from shared SaaS environments to fully private, enterprise-grade installations.
Nexus is proprietary & confidential software, licensed by Veloxs AI Inc. and is currently available to enterprises through a guided pilot program. Pilot partners receive licensed access, onboarding support, and direct engineering contact.